Introduction
There has always been (and there still is) confusion on terminology and usage of mutexes and semaphores. The main reason is that the term ‘semaphore’ has a different meaning depending on the context. We need to distinguish two contexts or levels:
- the concept and usage level, and
- the implementation level.
This article is about the concept and usage level: it explains two different use cases for which we need two different concepts (the solutions). The implementation level is not discussed here; we leave this for the next article in the series.
Two use cases
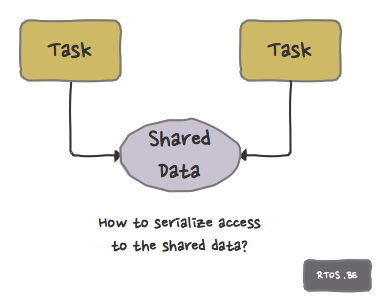
Use case 1: how to serialize access to shared data?
Data is shared between several tasks and, in order to keep the data in a consistent state, we need to protect it from concurrent access. In other words: access to the data must be serialized.
Examples:
- the ‘hello world’ example for this use case is: two threads and both threads increment a global variable i 10 times. The end result should be i==20.
- a list structure which is a shared between several tasks.
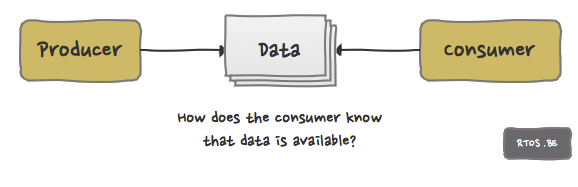
Use case 2: how does the consumer know that (new) data is available?
This use case is mainly about task synchronization: the interplay between producer and consumer must work smoothly. How does a consumer know that new data is available?
Examples:
- an interrupt service routine produces data which is consumed by an interrupt service task.
- a pipe of tasks: the output from one task is the input for next task.
- counting event.
Two concepts
Concept 1: the mutex
So how can we serialize access to shared data (use case 1)? One way to achieve this is to identify the critical sections in your code. A critical section is a piece of code (part of a function) from which the access to the shared resource must be atomic. At a certain moment in time, one and only one critical section is allowed to access the shared data. The first concept ‘the mutex’ is one way to implement a critical section. Mutex = MUTual EXclusion.
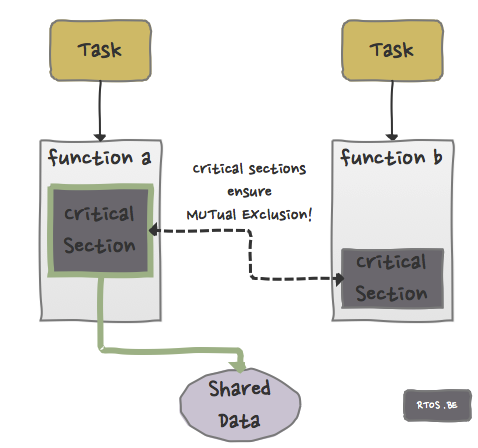
The mutex implements two operations:
- acquire: enter the critical section, or sleep if another task has already acquired the mutex, and
- release: leave the critical section. Other tasks now have the possibility to acquire the mutex.
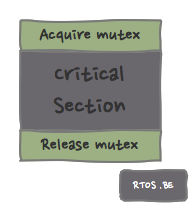
The concept of ownership is very important here: the task that acquired the mutex must release it as well! Bad things will happen when:
- another task releases the mutex, or
- the task never releases the mutex, and so on.
The exact behaviour is implementation dependent, as well as questions such as: what happens when the mutex is acquired two times (by the same task)??? Please review your mutex documentation 🙂
Ownership has other consequences as well e.g. it is prone to deadlocks and priority inversion (which we already introduced here).
Note that there are other ways to serialize access to data e.g. sending messages to the one and only task that manages the data. Or one can try to avoid race critical sections by using e.g. lock-less algorithms.
Concept 2: the semaphore
Use case 2 has several solutions as well: the consumer can poll for new data or – the other way around – the producer notifies or signals the consumer when new data is available. The second concept ‘the semaphore’ is applicable for the latter. The Greek word sema means sign or signal, and -phore means carrier (at least, according to merriam-webster.com). So a semaphore carries the signal from producer to consumer. Semaphore = signalling.
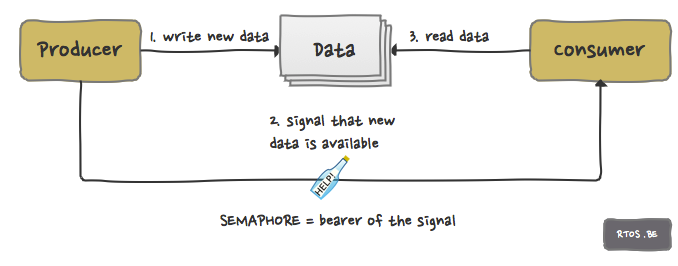
A semaphore implements two operations:
- signal: which is used by a producer to notify the consumer,
- wait: which is used by the consumer to wait for a notification.
In contrast to the mutex, a semaphore has no ownership. Producers and consumers are normally different tasks. Therefore, a semaphore is very suitable for ISR-IST communication: the ISR signals the IST when something new is available for processing.
In problems with multiple producers and/or consumers, a counting semaphore might be helpful (e.g. the large paying car park example). One must be careful though… Suppose you have two identical resources e.g. two printers which can be shared among several tasks. A counting semaphore seems to be the obvious solution BUT actually, it depends… If the task – after being signalled – still needs to retrieve the information (=state =a mutex to protect that state!) with which specific printer it has to communicate then probably two mutexes – one for each printer – is a better solution (ref).
But then… what is so confusing about mutexes and semaphores?
Because at the implementation level binary semaphores are typically used to implement the concept of mutual exclusion by mutexes. In next article we’ll see some examples. A binary semaphore is not the same as a mutex because their use case is different (and this might impact the high-level api, the debugging possibilities, etc… as well)!

Speak Your Mind