On this product-specific website, you can find all info about our brand-new VAWT design: the GreenT VAWT.
We welcome you to read about its great specs and unique features!

Illustrated Blog on Embedded Software Architecture
On this product-specific website, you can find all info about our brand-new VAWT design: the GreenT VAWT.
We welcome you to read about its great specs and unique features!

As long as real-time control and fail-safe operation is not a strict requirement, the GUI or another PC application could be used to control the Green4 via our rs232 serial protocol. The target software simply executes what is being demanded by the … [Continue reading]
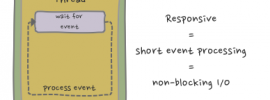
We need a GUI thread. ...is a common developer's reaction when the application only responds slowly to user clicks. The developer might be right: when some (gui) events require a lot of processing then having more than one thread, e.g. a GUI thread … [Continue reading]
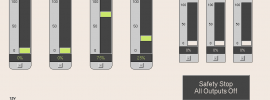
Introduction For most embedded projects it is good practice to have basic tooling for testing I/Os. I/O primitives such as 'read gpio', 'set pwm duty cycle', 'read adc', not only allow engineers to verify hardware and software drivers, it might also … [Continue reading]
red-black tree The even more advanced container we look at now is the red-black tree, which is a type of self-balancing binary search tree. Especially, interesting is the time complexity in big O notation: Action/Subject Average … [Continue reading]

Having the correct and proper enclosures, is a mechanical (and also a marketing) problem many electronics projects suffer from. It is also related to anticipated sales numbers. For big numbers, a custom enclosure which is produced with an injection … [Continue reading]
Choice of containers Information technology, even embedded devices, is about information gathering, processing or calculation, and control. Input and data needs to be juggled around and maybe sorted. In this article, we want to point out some … [Continue reading]
I found the inspiration for this article while working on a consultancy job: Priority inversion. In computer science, priority inversion is a (potential) problematic scenario in scheduling in which a high priority task is indirectly preempted by a … [Continue reading]
Time for another update. The Green4 project is progressing steadily. In the last few months, we have been busy preparing the Green4 prototypes. Test software has been developed which is already very usable, but it is still in a state of flux as we … [Continue reading]
...and learn about Embedded Software Architecture
![]() RTOS bvba is a young company which was founded in 2012 by Pieter Beyens and Gert Boddaert. Please read our Mission Statement to find out our goals and initiatives. About us
RTOS bvba is a young company which was founded in 2012 by Pieter Beyens and Gert Boddaert. Please read our Mission Statement to find out our goals and initiatives. About us
![]() Kris Bellemans is a software engineer employed at Sioux Embedded Systems, Belgium. He is passionate about low-level programming, embedded Linux and technology and science in general and has 4 years of experience in the field of software engineering. For more information, check his LinkedIn profile.
Kris Bellemans is a software engineer employed at Sioux Embedded Systems, Belgium. He is passionate about low-level programming, embedded Linux and technology and science in general and has 4 years of experience in the field of software engineering. For more information, check his LinkedIn profile.
![]() Patrice's professional tag cloud: anything mobile, software design, explorer, Enterprise Architecture, Agile Coach.
Patrice's professional tag cloud: anything mobile, software design, explorer, Enterprise Architecture, Agile Coach.
http://blog.threeandahalfroses.com
![]() Luc has more than twenty years of experience in embedded systems and real-time behavior. He is specialized in Operating Systems and interactions between hardware an software. Besides owning his company Luperco, he performs research on real-time scheduling at the Vrije Universiteit Brussel (VUB).
Luc has more than twenty years of experience in embedded systems and real-time behavior. He is specialized in Operating Systems and interactions between hardware an software. Besides owning his company Luperco, he performs research on real-time scheduling at the Vrije Universiteit Brussel (VUB).
Recent Comments