In an earlier article, we talked about real-time behaviour, meeting deadlines and how a real-time OS operates. To recapitulate:
the highest priority task that becomes runnable pre-empts all other tasks and runs to completion (until it ends, yields or sleeps).
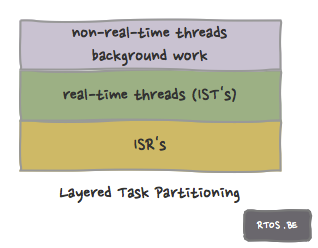
Also, we can have different layers of processing.
- high-to-low priority run-to-completion interrupts run first (all interrupts pre-empt running threads; also note that interrupt nesting could be possible depending on the design and processor),
- high-to-low priority run-to-completion threads,
- background processing.
layered task partitioning
The above reflects itself in the highly recommended method of layered task partitioning:
- Very short interrupt functions (ISRs) that only store the required information for further processing. They then signal the related thread to start working – depending on the priority – on the event or data. The real-time OS thread priority determines when it becomes runnable. The ISR should be system-friendly and allow other interrupts and tasks to do their thing as soon as possible.
- The prioritized threads (IST) do the processing in the specified deadline.
- Non-real-time and background stuff is done in very low priority tasks or even in ‘idle’ mode.
Optimize for responsiveness OR for throughput
However, the real world can force the system designer to make other decisions.
We also stated earlier, that to measure and determine worst case behaviour with regard to the deadlines, one must disregard processor or micro-controller cache. Indeed, looking at the above task partitioning method, it should be obvious that one can not depend on the cache having the right instructions or data at hand (unless one can ‘hand’-optimize what to cache of course). Often, in embedded processors, cache is (relatively) small (or even absent). ‘Cold’ or ‘hot’ cache can have a tremendous impact on performance.
To benefit more from cache (and thus run at higher performance levels), a task must monopolize the processor for a longer period of time. This could to be contradictory to the recommended method of layered task partitioning. Sometimes, it seems that responsiveness and throughput are different optimization targets.
An example: Suppose we have an interrupt signalling that data is available. We must move this data from peripheral memory before the next incoming data overwrites it. Then we should encode the data. We have thus three stages.
So logically we could assign the different task parts as follows:
- ISR : Signal IST that data is to be received
- Data IST: LOOP forever { Wait/Block for signal that data is to be received; copy data from register to memory buffer; signal encoding IST; }
- Encoding IST: LOOP forever { Wait/Block for signal that data to be encoded is ready; encode data; }
Unfortunately, a driver like this is not the only one in an embedded system. Usually, lots of drivers and subsystems are needed in the composition of the whole. Worst-case guaranteed response times – disregarding cache for the moment – can be designed in, but without cache acceleration effects, general performance could drop drastically: Even in such a way, that throughput suffers dramatically. In the above example, we have an interrupt firing at a specified rate, a context switch at the specified rate, memory transfer operations, another context switch at particular rate, processing on the data probably in combination with memory transfers, etc… After every (interrupt and/or thread) context switch, other code is probably needed: ‘Cold’ instruction cache is possible again. Moreover, other drivers are also causing the same cascade at another rate.
Can we do both?
To improve throughput, processing needs to be grouped in chunks and tighter loops. To improve performance, we need less interrupts and larger uninterrupted time-slices.
Practical advice:
- design the system with different layers of processing, they can always be combined later on.
- measure the performance of every sub-task with cache disabled.
- measure the performance of every layer with cache disabled.
- decide which sub-task to place in which layer, experiment and measure. Measure the performance of changed layers again.
- If real-time responsiveness and demands have been met, “group and tight-loop” non-real-time sub-tasks.
- If possible, diminish the number of interrupts in the system. Postpone until the last possible moment – but keep real-time properties in check.
So, in our example case, it could be that
- ISR : copy data from register to memory buffer, signal encoding IST only after e.g. 10 received data buffers OR when a timeout was triggered
- Encoding IST: LOOP forever { Wait/Block for signal that data to be encoded is ready; LOOP until no more data { encode data; } }
is more efficient and still meets the required deadlines! Simple but effective.

Speak Your Mind