Real-time scheduling in practice
In one of our previous items we talked about Real-time scheduling. Now, we want to show how priorities could be assigned in practice and how deterministic system response can be designed.
Deterministic response needs to take into account the worst case scenario: everything is happening at once, at the worst possible time (usually the beginning): the system must respond within a given time frame. The system could react faster, but – in order to be a hard-real-time system – it should never miss the dead-line.
Event frequency
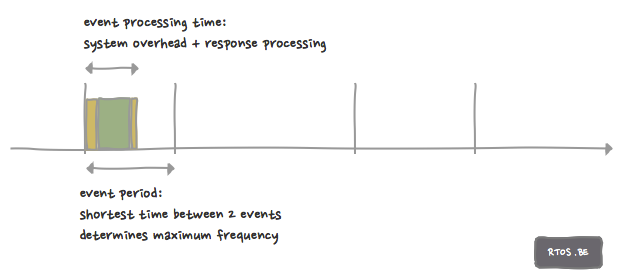
Periodic events on which the system must respond are defined by their maximum frequency, i.e. the shortest time between two events transformed in the number of times per second the event could occur: For example, the event fires, and the fastest time the next similar event could occur is 10ms later, this means the worst case frequency is 100Hz (100 times per second). It does not matter if this only happens in one in ten cases. At that time, the system must be able to handle it.
Event processing time
The second important parameter linked to the occurrence of a ‘trigger’ event, is the time it takes to respond to it: this can be defined as the entire reaction plus processing time related to the response, which is “as long as it takes to formulate an adequate answer plus the time it takes for the system to become ready again to respond to another event.”
Timely system response
We need those two parameters to successfully model the deterministic system response. Frequency is usually the easy one. For example, receive RS232 serial communication data with a single BYTE reception register (without FIFO/DMA) at 9600 baud, will give you 9600/(8 bits + 1 start bit + 1 stop bit) or 960 ‘there-is-a-byte-in-the-reception-register’ events per second. If a single byte must not be lost, the system must read the receive register before the next byte arrives (and overwrites the previous content).
So, – unrealistically – if the system has nothing else to do, it can take 1/960 seconds to read the data from the reception register. Hopefully, it takes less time to respond to the event, so the system can also do something useful with the data :). But “to measure is to know” or “the numbers tell the tale” or whatever. So in order to know the response time, you need to measure the time it takes to execute the required code. That might be tricky if you know the processor or micro-controller you will be using, but it might be guesswork if the platform selection has not been made yet. In that case, one might revert to known similar processors and acquire the data there, and try to extrapolate with a large error margin. At a later stage in development, it needs to be checked and re-evaluated. So in short: determine the processing time without cache impact by measuring code execution of isolated tasks (thus without other higher priority tasks running). This will be easier if the code does not contain complicated branches or loops. Always go for the worst case execution path.
Cache impact
Another caveat in code execution measurement is the cache issue. To measure the worst case behaviour, data and code cache on the processor or micro-controller must be disabled (or poisoned)! Embedded processors usually do not have a huge cache, so at a time the ‘event’ occurs, chances are that the cache is filled with other code and data than is required to perform the response. If one cannot disable the cache, a low priority task can be used to poison the cache and flush out code and data referenced by the task under scrutiny.
System load
We simply define ‘System load’ as the percentage of the time the system is busy processing; or in other words, the percentage of time, the system is NOT idle. Even systems with very little load could miss deadlines and then these cannot be categorized as ‘real-time systems’. It is difficult – but not impossible – to have or design heavily loaded real-time systems.
Assigning priorities: example
Things will get clearer with an example.
Three events. A, B and C.
A – frequency 10Hz (every 100ms), it takes 90ms to respond; if it were the only task, it would lead to 90% load on the system.
B – frequency 500Hz (every 2ms), it takes 150µs to respond; 7.5% load
C – frequency 100Hz (every 10ms), it takes 100µs to respond; 1% load
Which one is more important? Which of the events should get the highest priority? Rate Monotonic Scheduling (RMS) and Earliest Deadline First (EDF) e.g. each will provide an answer and can give some insight in the matter. E.g. with RMS, the task with the highest occurrence rate gets the highest priority: B, then C and then A. For more theoretical detail, look here.
If it is still unclear whether the system is ‘schedulable’, you can try the following heuristic:
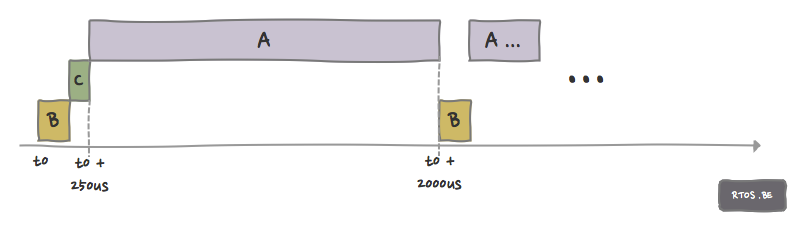
All events A, B and C occur at the same time, t0.
Since B is regarded by the developer as the most important task, it gets the highest priority. C gets the second highest priority. It is clear that A cannot get the highest priority since then the other tasks would miss there deadline very soon.
A gets priority 3 (lowest), B gets priority 1 (highest), C gets priority 2 (middle).
At time t1 = t0 + 150µs = 150µs, B is finished, C is scheduled to run.
At time t2 = t0 + 150µs + 100µs = 250µs, C is finished, A is scheduled to run.
At time t3 = t0 + 2000µs , A is not yet finished but B needs to run and is scheduled.
At time t4 = t0 + 2150µs = 2150µs, B is finished, A is scheduled to run and continues (already done 2000 – 250 µs = 1750 µs of the 90000µs it needs to complete it) processing…
At time … and so on. You make a nice drawing of it and visually see of this system meets all deadlines.
More to come
These scheduling and priority schemes depends on the fact that tasks have no (b)locking inter-dependencies, thus no priority inversion problems or deadlocks. In a next episode, we will demonstrate how this can be achieved.

Well… first of all you assume you have an OS with several/unlimited levels of priority, and that the OS itself (and some of its standard tasks) does not interfere with your tasks/priorities.
Secondly, the most important thing is that your driver code (most probably the part running under interrupt or in a high priority task) is able to free up the hardware before the next event occurs. That is enough to guarantee that you don’t miss any events. The actual processing of the event (doing something useful with it) can be postponed to a later point in time (i.e. running under task context). When your system is under a 100% load, the tasks can then decide which events will finally be dropped (i.e. decided to not do anything useful with it in the end).
Any real RTOS must have a preemptive priority-based scheduler. The number of available priorities are RTOS (or configuration) dependent. On most RTOS, the number of available priorities equals the number of available tasks (or allocated Task Control Blocks). More ‘fancy’ RTOS, have hybrid modes in which tasks of the same priority either yield voluntarily or are scheduled in a round robin fashion, unfortunately this might undermine the predictability (or at least make it far less easy to determine the tasks runtime durations).
Any RTOS OS-task (if such tasks exist in the OS) must adhere to the preemptive priority-based scheduling; if any runnable task’s priority is higher than a currently running task, it must be scheduled immediately and thus preempt the current running task whether this is an OS-task or not. Any (RT)OS not following these rules, is NOT an RTOS.
A good (software) driver must indeed free up the hardware before the next event occurs, and this is true for even non-real-time tasks on non-RTOS or general purpose OS. However, this is not the complete picture of the Event – Response flow. An RTOS enables you to predict with 100% certainty when (and if) there will be a Response in time (before the given deadline has elapsed). For argument’s sake, a fictitious example: small comfort if you can determine that one of your car’s micro-controllers is able to read out the wheel spin sensor on time (free-up the hardware register before the next event occurs), but is too late to engage the ABS (and disengage the brakes for very short periods of time) and/or disengage the ABS because some other task could not be preempted. Indeed, there is even a difference between soft real-time and hard real-time. We need and describe hard real-time systems (built on real RTOS) here.